
2026 March 02
From MVP to Enterprise: What Changes Under the Hood
A deep technical analysis of what truly changes when a SaaS product evolves from MVP development to enterprise software development — architecture, scalability, security, DevOps maturity, and long-term system reliability.
Executive summary
A successful MVP often proves the business, not the system architecture. The same shortcuts that make MVP development fast—single-tenant assumptions, informal boundaries, minimal automation, “good enough” security—become liabilities when customer count, data volume, team size, and contractual expectations rise. This is why products that succeed as MVPs frequently struggle during scaling: the architecture never transitions from “validate quickly” to “operate and evolve safely.”
Enterprise systems are less about a specific pattern (monolith vs microservices) and more about repeatable operations: clear service boundaries, intentional reliability, measurable performance, and controls for security and compliance. Frameworks such as the AWS Well-Architected pillars (operational excellence, security, reliability, performance efficiency, cost optimization, sustainability) formalize these dimensions because they are persistent sources of risk in real production environments.
The practical takeaway: building an enterprise-ready product is an architectural evolution. It usually involves deliberately increasing modularity (often starting with a modular monolith), hardening data management and failure recovery, introducing mature DevOps practices (CI/CD, IaC), and building monitoring and observability so that performance and reliability are operationally measurable rather than anecdotal. This work is not “polish”; it reshapes system economics by reducing technical debt interest and preventing brittle scaling.
Introduction
Most SaaS teams can describe what their MVP does, but fewer can describe what their system guarantees. Early customers tolerate manual processes, occasional downtime, and operational quirks because they are buying the product’s value proposition, not its operational maturity. Enterprise customers often invert that priority: the product is evaluated as much on assurance—availability, auditability, breach posture, and change control—as on features. The result is a common failure mode: feature velocity continues, but operational risk grows faster than the business can absorb.
A useful way to frame the transition is that MVPs optimize for learning speed, while enterprise systems optimize for safe change under load. That difference affects almost every “under the hood” decision: whether boundaries are enforced or implicit, whether failures are handled explicitly or by retries and hope, whether environments are reproducible, and whether performance is measured with high-fidelity telemetry. These are architectural properties that are expensive to retrofit late, but also expensive to overbuild early—so the right answer is staged evolution, not maximal upfront design.
Why many MVPs fail when scaling and why architecture must evolve
Scaling stress is rarely linear. At small scale, an outage affects a handful of users; at enterprise scale, it can violate SLAs, trigger support escalations, and create reputational risk. Likewise, at small scale, “deploy on Friday” might be survivable; at enterprise scale, change management becomes a discipline because the cost of incidents rises and the number of interacting components grows. The AWS Well-Architected reliability guidance emphasizes designing for resilience, consistent change management, and proven recovery processes—precisely because failures are expected, not exceptional, in real systems.
A second scaling cliff is organizational: the team grows, code ownership becomes diffuse, and implicit design knowledge disappears. If boundaries are informal, teams collide in the same code paths and database tables, increasing coordination cost and regression risk. This is the moment many teams “choose microservices” to regain velocity—only to discover that distributed systems introduce their own tax: remote calls fail, consistency becomes harder, and operations complexity rises. In Fowler’s analysis of microservice trade-offs, distribution and operational complexity are first-order costs; adopting services before you have the operational maturity to run them often reduces throughput rather than increasing it.
Finally, the absence of measurement becomes fatal. MVPs can “fly by sight” because few code paths matter and the system is understandable. Enterprise systems require observable behavior: latency, error rates, capacity headroom, and customer-impact signals. The Google SRE guidance is explicit here: if you can only measure a small set of user-facing signals, focus on latency, traffic, errors, and saturation, then build SLOs and alerting aligned to user experience. Without that foundation, scaling creates alert fatigue, slow incident response, and unreliable prioritization.
What an MVP actually optimizes for
Speed. A well-executed MVP is engineered to reduce time-to-learning, not to maximize software scalability. Practices like “monolith first” frequently win because they reduce coordination overhead and keep development and debugging simple while the domain is still fluid. Fowler explicitly argues for starting with a monolith even if microservices may be beneficial later, because early distribution complexity can slow learning.
Validation. MVP scope is constrained to validate value: proving a workflow, pricing, channel fit, or retention loop. This often means hard-coded assumptions (single tenant, one region, one plan tier), simplified authorization, and a coarse data model that matches the first business narrative. These choices are rational—provided they are documented as reversible decisions. The technical risk begins when reversible shortcuts become “the way things are” and the system’s future change cost is ignored.
Limited scope. MVP architectures tend to have one dominant data store and a single deployment unit. That reduces integration points and makes early iteration faster, and it is consistent with operational excellence guidance that encourages small, reversible changes—except MVPs often skip the “reversible” part by lacking automation, rollback paths, and tested recovery. Well-Architected operational excellence design principles emphasize safe automation and frequent, reversible changes; those principles become increasingly mandatory as change volume grows.
Intentional trade-offs. MVPs usually accept a narrower security posture and fewer formal controls, because enterprise-grade controls (audit trails, segregation of duties, formal incident management) cost time. Similarly, MVPs may postpone comprehensive telemetry and rigorous release processes, even though those omissions become expensive later. This is not a moral failing; it is a business optimization—until the business enters an enterprise buying motion that demands assurance evidence.
The contrast below summarizes typical optimization targets. It is a synthesis of the change-management and reliability framing from AWS Well-Architected, the measurement posture from Google SRE, and the delivery-performance framing from DORA.
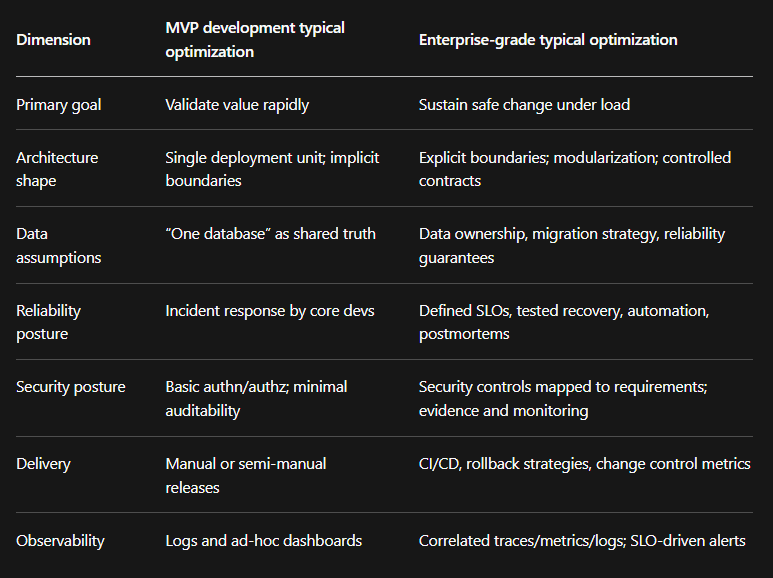
What enterprise systems require
An enterprise system is characterized less by technology choices than by properties. The most practical way to discuss these properties without hand-waving is to anchor them to primary frameworks: AWS Well-Architected for cloud system qualities, Google SRE for reliability measurement and operations, OWASP for application security verification, and DORA for delivery performance.
Scalable software architecture as a set of guarantees. “Scalability” is frequently misread as “handle more QPS.” In practice, scalable software architecture also means scaling teams and change volume. This requires consciously choosing coupling boundaries, managing failure modes, and ensuring changes remain reversible. AWS reliability design principles explicitly call out automatic recovery from failure driven by meaningful KPIs, and the reliability pillar frames resilience and change management as foundational. Those are architectural requirements, not operational afterthoughts.
Modularization and service boundaries. Enterprise systems need boundaries that are enforceable and evolvable. Many teams reach for microservices to obtain independent deployability, but microservices impose distribution costs: latency, partial failures, eventual consistency handling, and significant operational overhead. Fowler’s trade-off analysis is blunt: distributed calls inherently fail and operations complexity rises because you’re deploying and observing many services. A pragmatic evolution is to first build a modular monolith—one deployable unit with deliberate modules and internal APIs—then extract services when organizational or scaling pressures justify the added complexity.
Security and compliance as engineering constraints. “Enterprise-ready” commonly implies alignment to criteria such as SOC 2 trust services (security, availability, processing integrity, confidentiality, privacy), and often ISO/IEC 27001 for an information security management system. If you sell in Europe or process EU personal data, GDPR creates legal requirements for lawful, transparent processing and data protection obligations. These are not solved by a checklist at the end; they require architectural support: audit logs, access controls, data classification, retention and deletion mechanisms, and measurable incident response capability. OWASP Top 10 provides a baseline awareness model for critical application security risks, and OWASP ASVS provides a more testable specification of security requirements and verification depth.
Cloud infrastructure design for repeatability and failure. MVPs often treat infrastructure as “where the app runs.” Enterprise systems treat cloud infrastructure as part of the product. AWS operational excellence design principles emphasize defining operations and environments as code where possible, and the broader IaC definition is consistent: infrastructure should be provisioned and managed using code to keep environments consistent and reproducible. Whether the mechanism is AWS CloudFormation, Terraform, or another tool, the objective is the same: eliminate snowflake environments, reduce manual toil, and make change reviewable.
Monitoring and observability as default instrumentation. Classic monitoring answers: “Is it up?” Observability answers: “Why is it behaving this way?” OpenTelemetry defines observability as understanding internal state via outputs and positions itself as a vendor-agnostic framework for generating and exporting telemetry signals—traces, metrics, and logs. Google SRE adds the operational discipline: measure the four golden signals, derive SLOs, and alert on meaningful SLO violations to avoid paging on noise. In enterprise systems, this telemetry is not optional—without it, you cannot quantify reliability or support on-call engineering without burnout.
Performance optimization as a closed loop. Enterprise performance work is rarely a one-off “optimize a slow endpoint.” It becomes a loop: measure (high-cardinality telemetry where needed), diagnose bottlenecks, reduce variance (especially P95/P99 tails), and prevent regressions via automated tests and continuous profiling where applicable. Distributed systems make this harder, because latency is additive across hops and failures are partial; hence the close coupling between observability instrumentation and performance engineering. The presence of mature tracing is often the difference between “guessing” and “knowing.”
DevOps maturity and delivery performance. Enterprise-scale delivery is about reducing batch size and making release risk measurable. Fowler’s definition of CI emphasizes integrating at least daily with automated builds and tests to surface integration errors early. DORA metrics formalize delivery performance: deployment frequency, lead time for changes, change fail rate, and failed deployment recovery time (plus evolved additions such as deployment rework rate). This framing is useful because it ties architecture and process to outcomes: if your system is not modular enough to deploy safely and frequently, or not observable enough to recover quickly, those metrics expose the constraint.
Data management and reliability engineering. As systems scale, data becomes the long pole: migrations, contention, and recovery. Read scaling is frequently addressed with read replicas; AWS describes read replicas as read-only copies that reduce primary load by routing read queries, and the RDS PostgreSQL documentation highlights operational constraints and promotion behavior. For broader reliability and evolution, replication strategies matter: PostgreSQL logical replication is explicitly designed to replicate data objects and changes based on replication identity, enabling more fine-grained control than physical replication. These are tools, not silver bullets—each introduces operational responsibilities (lag monitoring, failover decisions, consistency models).
The hidden cost of not refactoring
The argument for refactoring is not aesthetic; it is economic. The Software Engineering Institute frames technical debt as the tradeoff between rapid delivery and long-term value: shortcuts can pay off now, but if unaddressed they create rework costs that can erase early gains. At scale, that “interest” is paid in slower feature delivery, more regressions, and increased operational risk.
This is why refactoring legacy systems is best understood as continuous maintenance of change cost. Martin Fowler defines refactoring as restructuring software without changing observable behavior, using small behavior-preserving steps to reduce risk. That definition matters operationally: enterprise systems cannot afford long periods of feature freeze for rewrites, and incremental refactoring enables evolution while continuing delivery.
The operational dimension is equally important. Fragile production environments are often a symptom of unmanaged debt: manual deployments, inconsistent infrastructure, unclear rollback paths, and alerting that pages humans for symptoms rather than customer impact. Google’s SRE guidance promotes blameless postmortems precisely to shift learning from “who caused it” to “what system conditions allowed it,” so the architecture and process improve over time. Without that feedback loop, teams repeat incidents and become risk-averse, which further slows delivery.
A practical way to reason about refactoring decisions is to compare intervention types. The table below summarizes trade-offs implied by incremental refactoring definitions and by Well-Architected and SRE guidance that emphasizes small, reversible changes and learning from failures.
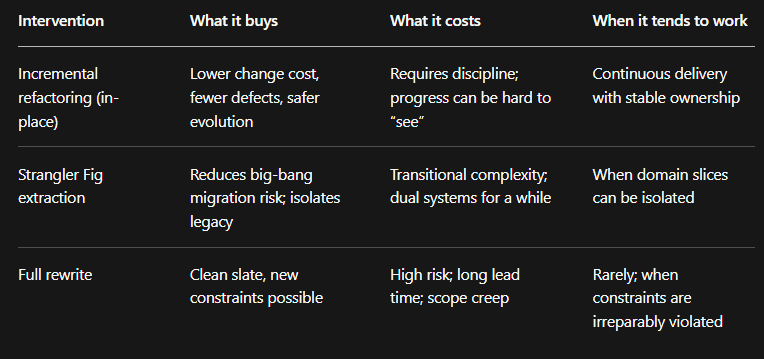
Architecture evolution practical examples
The patterns below are not prescriptions; they are representative sequences that appear repeatedly in real SaaS scaling journeys, especially when moving from an MVP to an enterprise-ready product. They align with primary guidance favoring incremental change, explicit recovery, and measurable outcomes.
Scenario: monolith to modular architecture (without premature microservices). A common first move is to formalize internal modules, define stable internal interfaces, and enforce dependency direction. This is often enough to allow multiple teams to work with less interference while keeping deployment simple. Only when modules require independent scaling, independent release cadence, or distinct reliability envelopes does service extraction start to pay off. This sequencing respects the microservice trade-offs: distribution and operations complexity are real costs, so you want to “buy” them only when you will use the benefits.
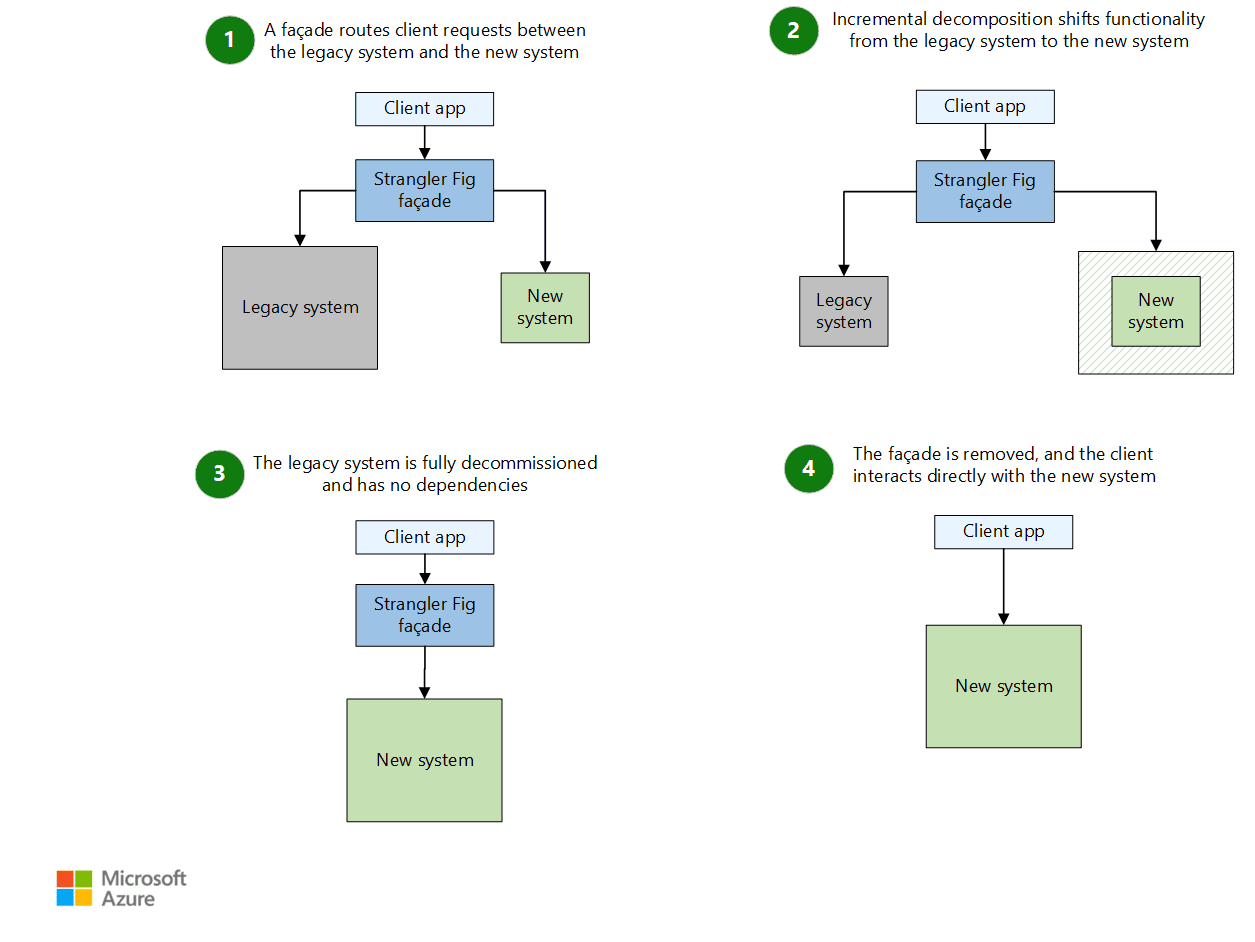
Scenario: adopting the Strangler Fig pattern for legacy modernization. Strangler Fig is an incremental replacement approach: new functionality is built alongside the legacy system, traffic is routed to the new component for a slice of functionality, and the legacy surface area shrinks over time. Fowler’s description grounds the metaphor and the incremental nature of the pattern, and his more recent writing shows it used to replace domains gradually rather than via big-bang rewrites. In practice, the architectural challenge is transitional: you must maintain two implementations and a routing layer, and you must ensure consistent observability across both so incidents remain diagnosable.

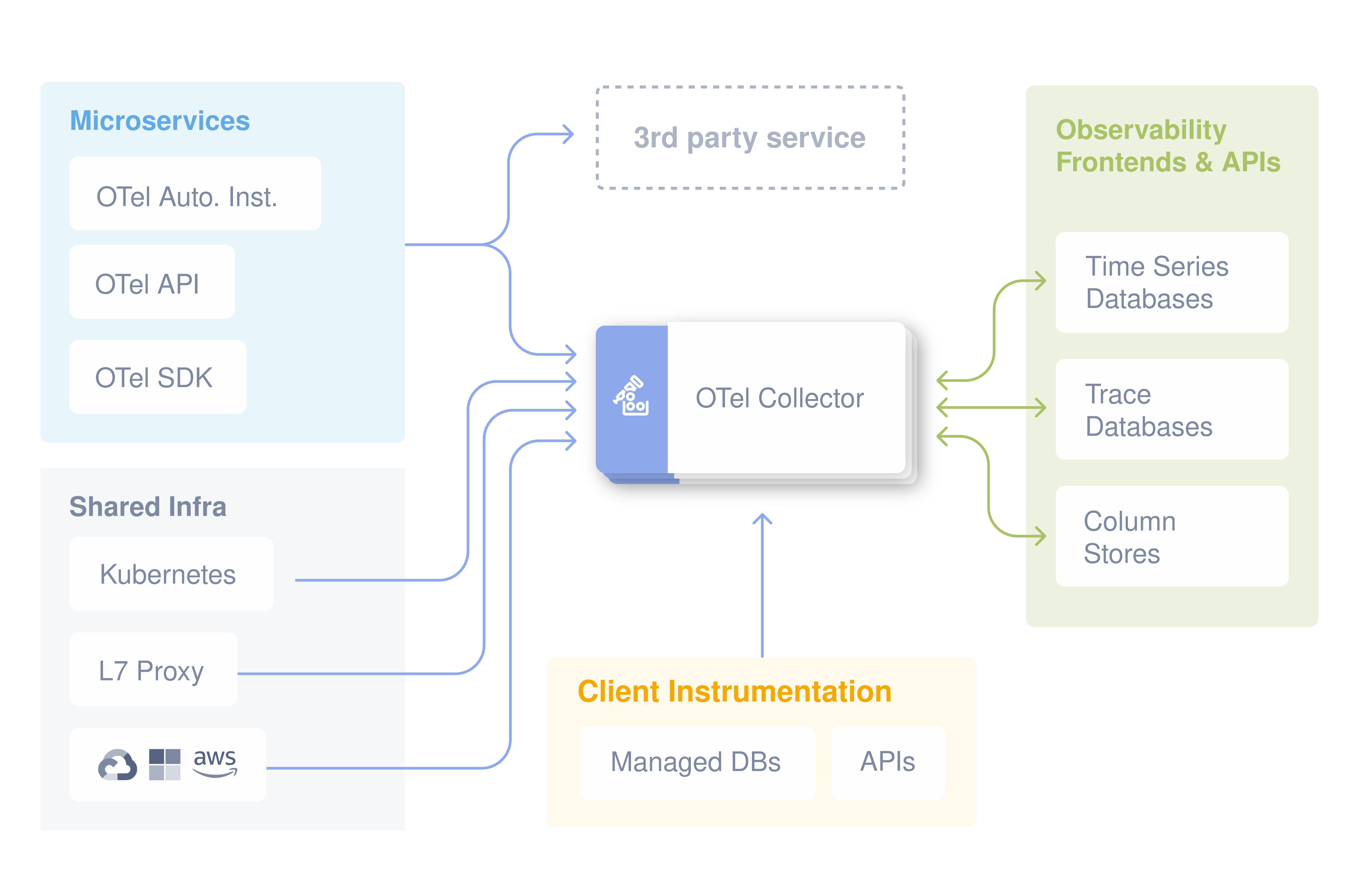
Scenario: improving database scalability and reliability. Teams commonly start by separating read traffic via read replicas, because it delivers immediate capacity gains for read-heavy workloads and can be adopted incrementally. AWS documentation is explicit that replicas are read-only and describes constraints and promotion behavior; these details matter, because they define your failure and recovery playbook. When the challenge shifts from read throughput to evolution (zero-downtime migrations, selective replication, multi-system integration), logical replication becomes relevant: PostgreSQL documents it as replication based on replication identity with fine-grained control, which is useful for controlled data movement and decoupling. Each step adds operational duties—lag, schema compatibility, and failover semantics—so observability for replication health becomes part of “done.”
Scenario: introducing proper CI/CD and infrastructure automation. The goal here is not “more tools,” but lower change risk via repeatability. CI, in Fowler’s definition, is frequent integration verified by automated build and tests to catch integration errors early. From there, the architecture is pressured to support safer deployments: smaller blast radius, feature flags, rollback paths, and deterministic environments. Infrastructure as code (AWS framing) enables environments to be provisioned and supported using code rather than manual steps, supporting review, reproducibility, and rapid recovery. DORA metrics then become the feedback: if lead time is long or change fail rate is high, architecture and process are not aligned yet—often due to hidden coupling, missing tests, or insufficient observability.
A final engineering detail that becomes disproportionately important at scale is failure behavior in distributed communication. AWS guidance on retries and idempotency is direct: APIs with side effects are not safe to retry unless idempotency is provided, and Well-Architected reliability best practices include explicit guidance to make mutating operations idempotent. This is the kind of “under the hood” change that customers never see, but it dramatically reduces incident severity and data corruption risk—especially as systems introduce async pipelines, background jobs, and partial failures.
Conclusion
MVP development and enterprise software development are different phases, not different levels of effort. MVPs optimize for learning speed through constrained scope and tolerable shortcuts; enterprise systems optimize for longevity: safe, frequent change under load, measurable reliability, and provable controls for security and compliance. Frameworks like AWS Well-Architected and Google SRE are valuable precisely because they encode recurring failure modes—change without reversibility, reliability without measurement, and complexity without operational capability.
Investing in scalable architecture is therefore not “over-engineering”; it is building the structural capacity to scale customers, teams, and product surface area without compounding risk. In practice, that investment usually looks like deliberate modularization, improved data durability and recovery, mature observability and incident learning loops, and automation that makes the production environment reproducible. Done incrementally, it is a strategic way to reduce technical debt interest while keeping delivery moving.
For companies crossing this boundary, the most reliable outcomes tend to come from engineering teams that have already lived through the trade-offs—knowing when to keep a monolith, when to extract services, how to sequence compliance controls, and how to operationalize performance optimization with real telemetry. That experience is less about “big rewrites” and more about designing an evolution path that preserves momentum while increasing assurance.
Might be interesting for you
Embracing PWA Trends for Outstanding User Experience
Progressive Web Apps (PWAs) are transforming the modern web. Learn how PWAs enhance user experience and engagement by combining the best features of web and mobile apps.

Creating Impactful Landing Pages with React and Framer Motion
Learn how to craft visually appealing landing pages using React combined with the powerful animation library Framer Motion to boost user engagement and conversion.

Leveraging React's Context API for Global State Management
Discover how React's Context API provides a simple yet powerful way to manage global state in your applications without the complexity of Redux or other libraries.